
Custom programming languages make agents really, really good
Agents are good at both creating and using new domain-specific languages
You’re probably sleeping on how effective domain-specific languages have become in the last few months. If you’re building a product on top of LLMs and agents (and even if you aren’t, really), you should probably be making DSLs to solve problems.
DSLs, for the uninitiated, are little languages crafted to attack a particular problem domain. Wikipedia alleges that even HTML is a domain-specific language; maybe that’s true, but I don’t really mean such broadly-used languages. Instead, I mean little miniature languages that you use to solve a problem, and which you don’t even necessarily share with the outside world.
Some examples of the kind of DSLs I mean, at Firetiger, include:
- A SQL dialect with constrained capabilities, used internally to query our data lake on customers’ behalf
- An integration test specification language which uses inline HTTP Requests and a special tagging grammar to express expectations
- A simple plain-text filtering language based on AIP-160 for expressing queries over API resources
DSLs like this hit a lot of sweet spots for LLMs. You can make them extremely token efficient, and enforce hard security boundaries. You can translate high-level LLM intent into a ton of deterministic code, ensuring good behavior and guardrails at the (custom) compiler level.
And Large Language Models are very good at learning and working with DSLs. Maybe this shouldn’t come as a surprise; they are language models after all. A small bit of documentation generally is enough to set them off and running, and reasonable error messages let them course-correct even when they go wrong.
In fact, when LLMs misuse your DSL, they’re often providing very helpful signal on improvements you could be making. Like, if they try to use some inline function called extract_timestamp(...), and they get an error, you can capture their failed tool calls, and then prioritize making a timestamp-extraction function in your little mini-language.
You don't have to get fancy to get the LLMs to use your DSLs. I'm not talking about wizardry like grammar-constrained decoding which powers structured outputs. This is just old-fashioned tool calls - you give the LLM a tool like eval(str) (or query(str), or search(str), as we'll see in examples below) and let it rip.
Your coding robot is good at this
So, they’re a really strong tool in today’s software landscape. But you might be thinking this sounds like a lot of work. Aren’t languages hard to make? Aren’t these things going to be a nightmare to maintain?
No! They’re not that bad at all! You should try!
LLMs are not perfect code authors. They fall into ruts, they can be uncreative and blindly repetitive. But those tendencies make them very good at writing tedious-but-well-traveled code, like recursive descent parsers.There is a tremendous corpus of existing code in this arena and your LLM coding agent of choice is almost surely capable of writing a pretty good parser pretty quickly. Look, grug agrees - a simple parser is not as complicated as you think, surprisingly simple to maintain, and very very powerful.
A note on testing
A more subtle benefit of asking your LLM to write a parser is that parsers are perhaps the single best fit for test-driven development you can imagine. You have input strings of text, and you have rigid expectations about the way the syntax ought to be parsed.
That’s nirvana for a coding agent. When asked to write test cases for a parser, you can practically hear Claude cackling and rubbing its hands together with delight as it exercises all sorts of wild token sequences and makes sure the parser works.
Fuzzers are straightforward too; you can get to really broad and solid confidence in the code through entirely automated means. These are testing random, untrusted inputs for weaknesses in your system.
This is useful, but it’s particularly important for the philosophical lesson it reveals: you can use domain-specific languages to establish a trust boundary. If you have agents who can only interact with your system through these structured languages, it acts as a boundary layer, you can test the hell out of that boundary and build a lot of confidence that your demonic non-deterministic adversarial agents are well-constrained.
A few examples from Firetiger
We’ve used this pattern a few times with great success. I’ll dig into a couple of examples.
Confit SQL: A query language for data lakes purpose-built for agents
SELECT
time,
resource.attributes.service.name AS service,
resource.attributes.service.namespace AS namespace,
resource.attributes.tenant.id AS tenant_id,
attributes.organization.id AS organization_id,
body.text AS message
FROM "opentelemetry/logs/executor-scheduler"
WHERE
time >= NOW() - INTERVAL '1 hour'
AND severity_number >= 9
ORDER BY time DESC
LIMIT 20;
An example snippet of Confit SQL
At Firetiger, we run a big multi-tenant data lake of logs, metrics, traces, and other telemetry signals. We let agents query this data.
For a while, we wandered around trying to make a good query interface. BigQuery? Presto? Prometheus? DuckDB? These off-the-shelf options kinda-sorta worked, but we were constantly running into worst-case scenarios in performance and runtime, as agents would write queries blissfully unaware of the size of the tables they were querying or how they are partitioned.
In addition, those languages are full of escape hatches that have worrying security implications. It’s all fun and games until your LLM starts writing queries that call read_text for miscellaneous things on the server’s filesystem.
So we made a query language! We call it Confit SQL (the name is derived from a tortured series of inside jokes; I’ll spare you). It’s based heavily on DuckDB SQL, but with limitations and tweaks to suit our needs.
First, most obviously, we forbid most functions, with a narrow permitted list. Easy!
Second, at query evaluation time, we rewrite FROM clauses to inspect only permitted data files. To the agent, it thinks it’s writing “SELECT * FROM “opentelemetry/logs/billing-service””, but we take that and rewrite it, resolving the string literal table name into a subset of files that the agent should have read access to. This is a good example of enforcing security boundaries without having to trust the LLM!
Third, we can interpret the WHERE clause of the query, turning it into predicate expressions that we can apply against the data lake in highly customized ways - this is predicate pushdown.
But in our data layer, some predicates are more crucial than others. Telemetry data is naturally partitioned by time, at the storage layer, so it’s really important to filter queries by time. You can try prompting LLMs to tell them to always include a time filter, if you like. Good luck getting them to always do it though.
With a structured language like this as the agent’s interface, though, we can inspect the predicates and actually enforce the rule that they need to use timestamp partitioning. We return an error when they break this rule. This is tremendously powerful, in practice; it seems that most LLMs are quite well-trained to avoid tool uses that result in errors, so once you’ve thwacked them on the wrist for reaching for a poor query, they don’t make the mistake twice in that session.
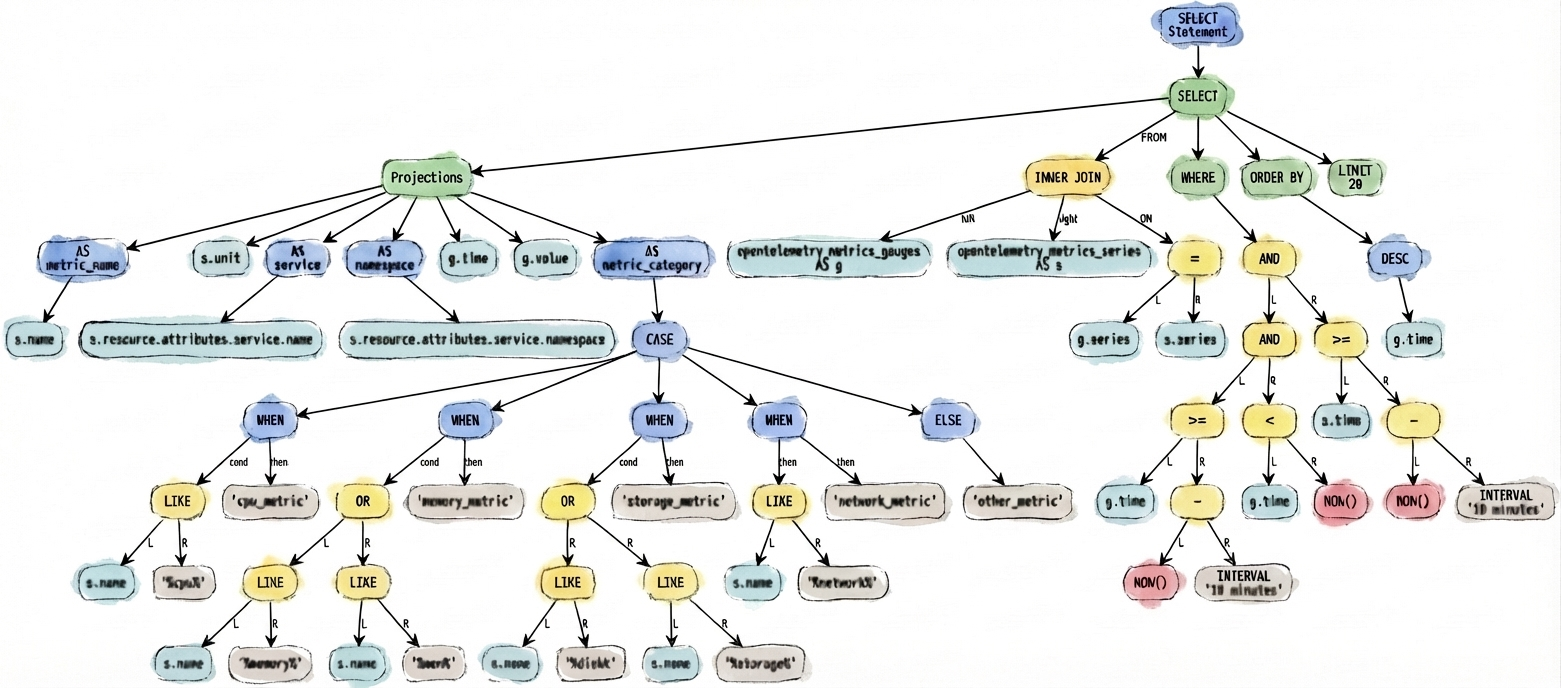
How we built Confit
The implementation of it is broken into three layers:
- A lexer defines the legal tokens. We use a simple hand-written, single-pass, byte-at-a-time lexer, with no lexer generator involved. It’s about 300 lines of highly repetitive code - this sort of thing:
func (l *Lexer) Next() Token {
l.skipWhitespace()
pos := l.pos
switch l.current {
case '(':
l.advance()
return Token{Pos: pos, Value: "(", Type: LPAREN}
case ')':
l.advance()
return Token{Pos: pos, Value: ")", Type: RPAREN}
case '[':
l.advance()
return Token{Pos: pos, Value: "[", Type: LBRACKET}
case ']':
l.advance()
return Token{Pos: pos, Value: "]", Type: RBRACKET}
case ',':
l.advance()
return Token{Pos: pos, Value: ",", Type: COMMA}
A bit of the lexer's internals
- A parser takes the lexer’s token stream and builds an abstract syntax tree. It’s just pure recursive descent. This is a lot of code, about 5,000 lines, and it has grown pretty organically as we've added features. For example, a couple of days about I added support for
BETWEENexpressions, which are sugar for expressing conditional ranges, likeWHERE time BETWEEN now() AND now() - interval '2 days'. That change added another 100 lines or so to the parser.
func (p *Parser) parseEqualityExpression() (Expression, error) {
left, err := p.parseContainmentExpression()
if err != nil {
return nil, err
}
for p.match(lexer.EQUALS, lexer.NOT_EQUALS, lexer.IS) {
if p.currentType() == lexer.IS {
p.advance() // consume 'IS'
// Check if this is "IS NOT"
wrapWithNot := p.currentType() == lexer.NOT
if wrapWithNot {
p.advance()
}
right, err := p.parseContainmentExpression()
if err != nil {
return nil, err
}
isExpr := BinaryExpression{
Left: left,
Operator: BinOpIs,
Right: right,
}
if wrapWithNot {
left = UnaryExpression{
Operator: newUnaryOperator(lexer.NOT),
Operand: isExpr,
}
} else {
left = isExpr
}
} else {
op := newBinaryOperator(p.currentType())
p.advance()
right, err := p.parseContainmentExpression()
The parser is straightforward, if verbose
- An evaluator takes the parsed syntax tree, and actually does stuff with it. This includes computing predicate pushdown, figuring out how to rewrite queries to access the right data files, checking permissions, and validating requirements. This is where all the most complex logic lives. It's tested with fancier integration tests that actually run a backend data lake and verify that input queries match expectations.
It also houses all sorts of little optimizations to make life easier on the agents writing queries. For example, while you can try to prompt an agent to use static values (like static timestamps, instead of the dynamicnow()function) because they're easier to use in predicate pushdown, at some point you realize things will be simpler if you just rewrite the agent's queries without it knowing, turning all thosenow()s into static values automatically.
func foldNow(expr confitsql.Expression, now time.Time) confitsql.Expression {
return confitsql.TransformExpression(expr, func(e confitsql.Expression) confitsql.Expression {
f, ok := e.(confitsql.Function)
if !ok || len(f.Arguments) != 0 || !strings.EqualFold(f.Function.SQL(), "now") {
return e
}
return confitsql.CastExpression{
Expression: confitsql.StringLiteral{Value: now.UTC().Format("2006-01-02 15:04:05.999999999")},
TargetType: "TIMESTAMPTZ",
}
})
}Our evaluator does some constant folding, converting 'now' into timestamp literals that can be evaluated statically
Critically, our evaluator produces SQL expressions that can be evaluated more completely by a DuckDB query engine. You might say we're really transpiling from one dialect to another. This might feel like a cheap trick, but it's actually great: we get to live on top of the excellent years of effort that the DuckDB team has put in; we're just sprinkling our own features on top and cutting out dangerous pointy bits that we don't want our agents to step on.
This pattern of three layers is a good one to use when you're making these sorts of things. You can test each layer independently, and separating the concerns helps coding agents target their changes well.
160+: A little filtering language for resources
Confit SQL is on the bigger side for a custom language. Way at the other end of the scale is 160+, a tiny expression language used to take simple strings and turn them into careful, escaped SQL WHERE clauses that we can apply in our Postgres application database.
Input:
author.email:"*@firetiger.com" AND create_time > "2026-03-11T13:06:25Z"
Compiles into:
("body"->'author'->>'email' LIKE $1 AND "create_time" > $2)
With positional parameters:
$1 = '%@firetiger.com'
$2 = '2026-03-11T13:06:25Z'Example 160+ compilation
We store a lot of API resources in our database, stuff like customer-configured agents, detected issues, and information about deployments. These get stored through a somewhat unusual protojson encoding in Postgres (a story for another day) but are often manipulated directly by system agents.
It's completely reasonable for our agents to query the data in complex and novel ways, especially on behalf of users, who might ask very complex questions. By handing agents this 160+ querying language, we give them a compact and simple way to filter the data in the database without needing to, say, load all customer deployment information and scroll through it, burning up context tokens.
160+ is based closely on AIP-160, which is Google's little language for this sort of thing, but we have a few quirks, like supporting wildcard matches. We also support filtering on array-valued fields.
Both of those special features arose because we saw agents reaching for them in practice, and being surprised by their absence. This echoes the pattern Sonarly documented of listening to what agents are trying to do. You have to be a little careful with this and exercise judgement, but DSLs like 160+ give a way to gradually expand an agent's capabilities.
You should do this too!
These little languages let agents interact with large pools of data with just the right balance of expressiveness and safety. And when we find they're lacking sufficient expressiveness, we can gradually add capabilities.
This is really different than the conventional approach of cramming more tools with more parameters into the LLM's prompt. That approach is unwieldy and burns tokens real quick. If you're making list_issues and list_issues_for_user and list_issues_for_organization tools, I think you're doing it wrong. That's reasonably well known - too many tools makes the agent go mad.
But I think you're even doing it wrong if you stuff a zillion parameters into every tool call. You still are paying a lot of cost for all those permutations of possibilities, which are usually irrelevant.
There's an emerging trend of emphasizing code execution to deal with this problem, which is on the right track. Cloudflare's Code Mode is a particularly ambitious approach here that we really like.
But arbitrary code execution introduces its own problems, for most code languages. It's pretty rare that you actually want an agent to be able to absolutely anything, but that's what most programming languages are (of course!) designed to do. By making a narrow custom language for your particular needs, you can hand an agent a set of tools that are sized just-right, and far easier to adapt and grow as you learn what you need.
So go out and try it! If you want a simple approach, take an existing language and build a layer on top of it to scope down its capabilities. This lets you bootstrap off of a powerful substrate with a safer outer shell. Tell your preferred coding agent to give you a lexer and simple parser, and you're off to the races.
At Firetiger, we're exploring more uses of this. A few ideas we have in mind:
- Can we wrap a high-level programming language like Python to mask out capabilities, but let agents write durable scripts for repeated execution by our backend, not just one-off tool use?
- Can we make a common lingua franca for cloud metrics provider backends so agents can develop human-and agent-readable queries that compile into HTTP requests?
- What about policy languages for controlling notifications from Firetiger, so that agents can define rich trees of how novel issues should be routed to the right person in an organization?
Exciting times. Thanks for reading, and let us know how your custom languages work out!