
Introducing Firetiger
Observability is dead. Long live outcome engineering.
Today, we’re excited to announce Firetiger. You and your AI agents write code. Firetiger makes sure it works.
Our team, Achille, and I have plenty of incident war stories to share from our time helping build Cloudflare, Segment, Twitch, and more. The big outages made the news, but what hurt were the paper cuts along the way, the issues that happen when an innocuous change somehow breaks your most important customer on their most important day.
In the agentic coding era we live in with Cursor, Claude Code, etc: the volume of code changes going out each day is ever increasing, and there are still lots of paper cuts in prod. And observability vendors aren't actually incentivized to close this gap: they make money when you to write more data to them, not when you make your software more reliable.
Firetiger is the agentic operations layer for the agentic coding era. We combine production observability data, codebase understanding, and knowledge of your business to drive engineering toward outcomes. That means finding problems before your customers do, and fixing them before they notice.
We are also excited to announce our $7.6 million seed round, led by Sequoia Capital with participation from angels who believe in better software, including Matthew Prince, Calvin French-Owen, Nico Rosberg, Dane Knecht, Eleanor Dorfman, Jeff Wilke, and Alana Goyal.
You can sign up for Firetiger today, self serve. We charge for agents that directly make your software better and more reliable, not for observability data ingested, with plans starting at $599/month.
Your life without Firetiger
You build software. You are customer focused, and are building and shipping at ludicrous speed with the help of coding agents.
Your most important customer calls: the feature you shipped yesterday is (sometimes) unusably slow. They and their agents are losing confidence in your product.
You fish through observability dashboards, literally using a ruler on your monitor to line up changes going out and graphs looking funny. You drill in on p99.9. Murphy’s law of SaaS: long tail latency affects your most important customer at the worst time, and resulting log lines will be sampled out and totally invisible.
You ask Claude to figure out what’s wrong. It can’t figure the perf issue out looking at code; runtime info is needed, but it never got written down because you were trying to save money on “observability”.
You ponder your fate. Your inbox dings with an invoice from Datadog. It leaves you with a large bill, no clarity on whether your software is driving toward the outcome you care about, and an uneasy feeling that there must be a better way.

Observability is a half measure
Even in the age of agents, “good” observability requires significant human investment: your best engineers have to think carefully about what matters to your customers and business, and then translate that into specific instrumentation and alerts that are relevant and actionable.
On top of the cognitive load required, the “pay us for sending detailed data” pricing structure these tools have puts them in an adversarial position vs their customers: observability vendors make more money when you write more data to them, not when you make your software more reliable.
Firetiger directly drives toward software quality, not just pretty dashboards and eye-popping bills for data ingested.
And we work well with logs, metrics, traces, or whatever shape of event data you produce as your software works; we have no dogma on the “right way” to instrument code, because it just doesn’t matter any more. Our agents are more than capable enough to connect the dots between what you are trying to accomplish and how your software documents progress.
Observability is dead. Long live outcome-focused engineering.
Life with Firetiger is different, and better!
Firetiger closes the loop on software operations in a way that classic observability tools never did. Our agents combine data from production systems, codebase understanding, and knowledge of your business to understand how your software behaves, identify what excellence looks like, and cluster similar problems into units of work that coding agents can directly make progress on to improve your software autonomously.
Here is Firetiger finding a reliability issue in production, putting it in context, and steering Claude Code to fix the problem, all in Slack:
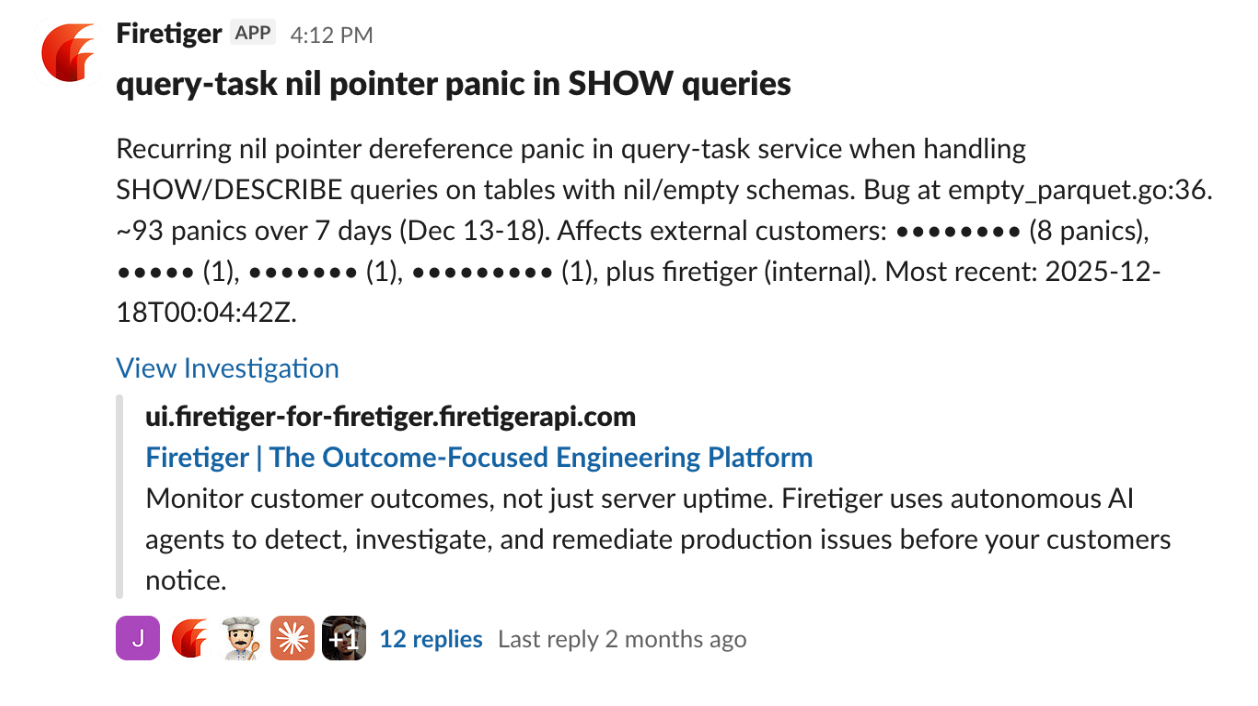
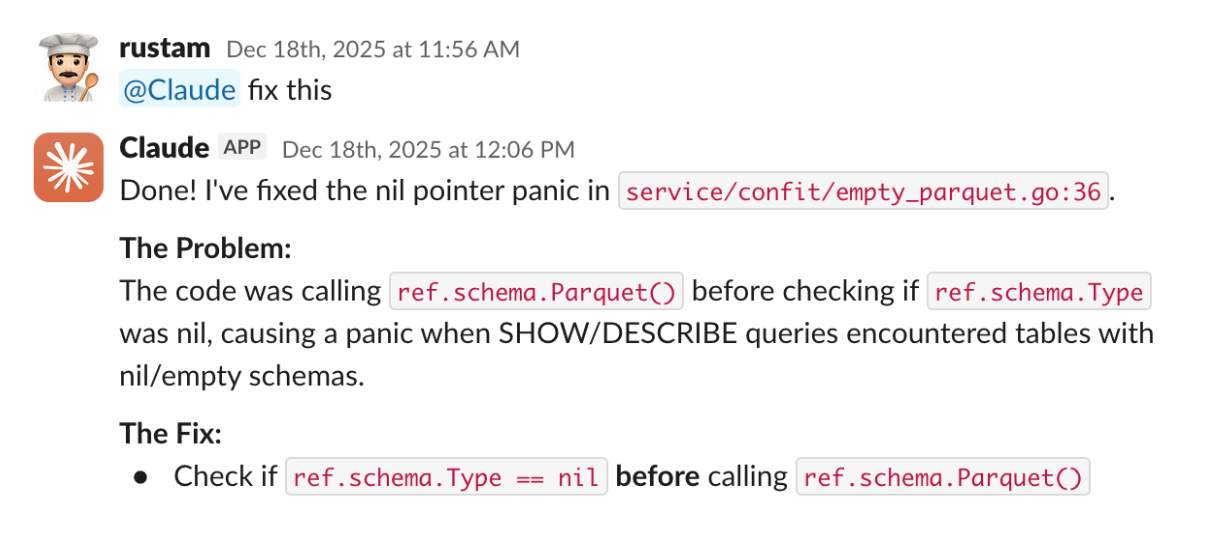
And then...
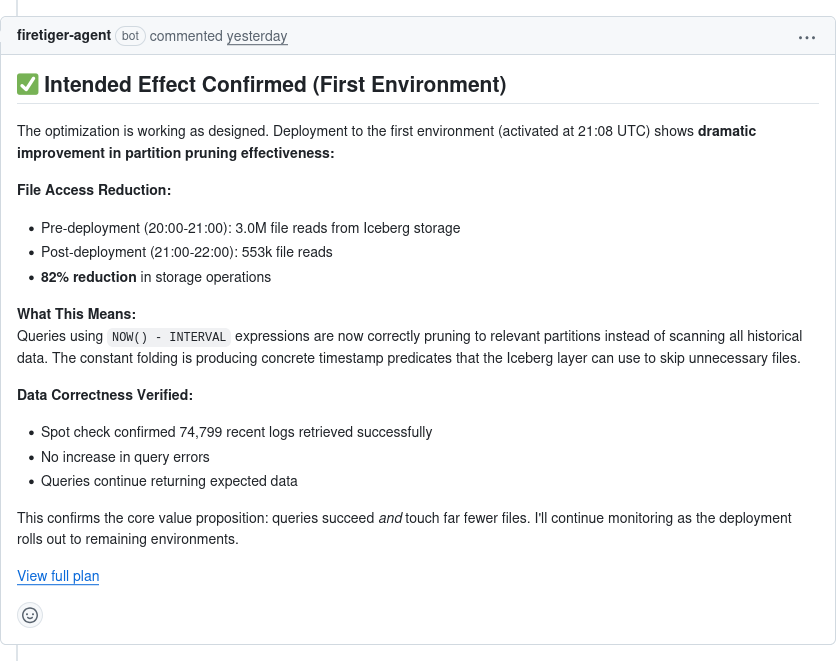
Or here’s Firetiger assisting an engineer deploying a performance optimization, coming up with a plan to measure its effectiveness once it hits the real world:

Once things are confirmed, Firetiger reports back with the good news:
How we do this
We’ve built an observability database for the agentic era (more on that here), and paired it with an agent and memory management system that allows you to hand off complex, nuance-filled workflows to a set of robots. Building a wide and deep data lake directly on S3 allows us to get the right context to our agents at the right time. Telemetry systems built for the human operations era capture limited amounts of detail, often encourage sampling, and are not capable of feeding agents the rich context they need to understand what is happening in production.
Just above the database, we’ve built a durable execution layer that enables agents to pursue long horizon tasks, interacting with incoming data, calling tools, and taking turns with LLMs in reliable ways. Agents are able to continuously consume telemetry and codebase information to assemble a knowledge graph with mappings of customers and dependencies. Agents propose runbooks and quality metrics they keep a close eye on.
The combination of purpose-built data lake, durable agent execution, and memory management systems allows our agents to deliver on operational goals over long periods of time.
Who’s a good fit for Firetiger?
Any team shipping software quickly that wants to raise the pace of deployment + operations to match the new high speed of code authoring. So, most teams. We work best with teams that have fully embraced agents in their development workflows, for whom totally hands-free software development (eg StrongDM’s setup) does not seem like science fiction.
An example agent that reliably delivers better software, and smiles: "find issues with and improve my database performance".
If you have one user or one billion, if you have software in production and wish it worked better, you should be using Firetiger today.
Why us, and why now?
We built this company because we have lived with these problems for too long.
I spent 7 years building Internet infrastructure products the world depended on at Cloudflare, serving over 4 billion users and hundreds of millions of events per second. I wrote the first incident management policy at Cloudflare, repurposing Supreme Court doctrine to define what an incident actually was (you know it when you see it). Achille was instrumental in building the Segment and Twitch data planes, serving as the technical lead on Segment’s Centrifuge project.
We spent years on the front lines, playing whack-a-mole with technical problems in production and apologizing to customers when we let them down, deeply unsatisfied by the tools available to prevent and remediate operational issues in production.
What do you mean it’s not possible to look at error rate by customer and deployment ID? How is it impossible to correlate a spike in LogLineX with a config change? Etc etc etc. People would mumble something about cardinality and cost and “this is just the way it is”. We thought: there has to be a better way, both on the data management and human-effort-required sides of the ledger.
So we started building Firetiger, where humans define what matters and agents figure out how to measure it, do the iterative watching, investigating, and improving of your software.
Then Claude Code happened.
As Claude Code got more capable, we shipped more. The changes got larger and more complicated. We understood our own code at a line-level less and less. And things broke often, not because the code was bad, but because we were shipping so much that change-related risk was stacking up faster than we could mitigate it. Fortunately, we were building the tools to solve our own problems.
This is why now: the combination of AI-assisted code generation and autonomous operations has crossed a threshold (some might say “takeoff”). Teams are shipping faster than ever, and the gap between "code written" and "code verified working in production" is growing every week. The tools built in the early 2010s for human operators staring at dashboards cannot close that gap, and cannot ensure that the software being built and shipped every day is delivering on outcomes that matter. You need agents driving agents to outcomes.
Welcome to the age of outcome engineering
We are very close to a world where human-less software factories hum with quality and purpose, where agents write code, agents verify it in production, agents find and fix what's broken, and humans steer the ship toward outcomes that matter. Firetiger is the operations layer for that world.
We built Firetiger because we spent years on the front lines of production operations, apologizing to customers for problems we should have caught first. We knew there had to be a better way. There is: agents that understand your codebase, your telemetry, and your goals, and that work around the clock to make your software better. This is outcome engineering.
Our early access customers have seen a 32% decrease in change-related issues within two weeks of installing Firetiger.
We’re on a mission to help builders sleep better at night and customers have confidence in the software they depend on.
Join us! You can sign up for Firetiger today, with paid plans starting at $599 a month and free trials available.
We’re also hiring! Get in touch if you want to build the future of reliable software in production.