
Incident postmortem in the age of AI agents
For approximately 8 hours on Sunday, March 1, 2026, Firetiger's ingest system for most customers was in a degraded state, failing to accept OpenTelemetry data and GitHub webhooks. The system is fully restored. We're sorry for the impact that this outage has had on your observability and have taken action to prevent issues like it from happening in the future.
There were three overlapping issues that conspired to cause this outage. The rest of this document will explain what went wrong, how we found the problem, and how we remediated it.
What went wrong
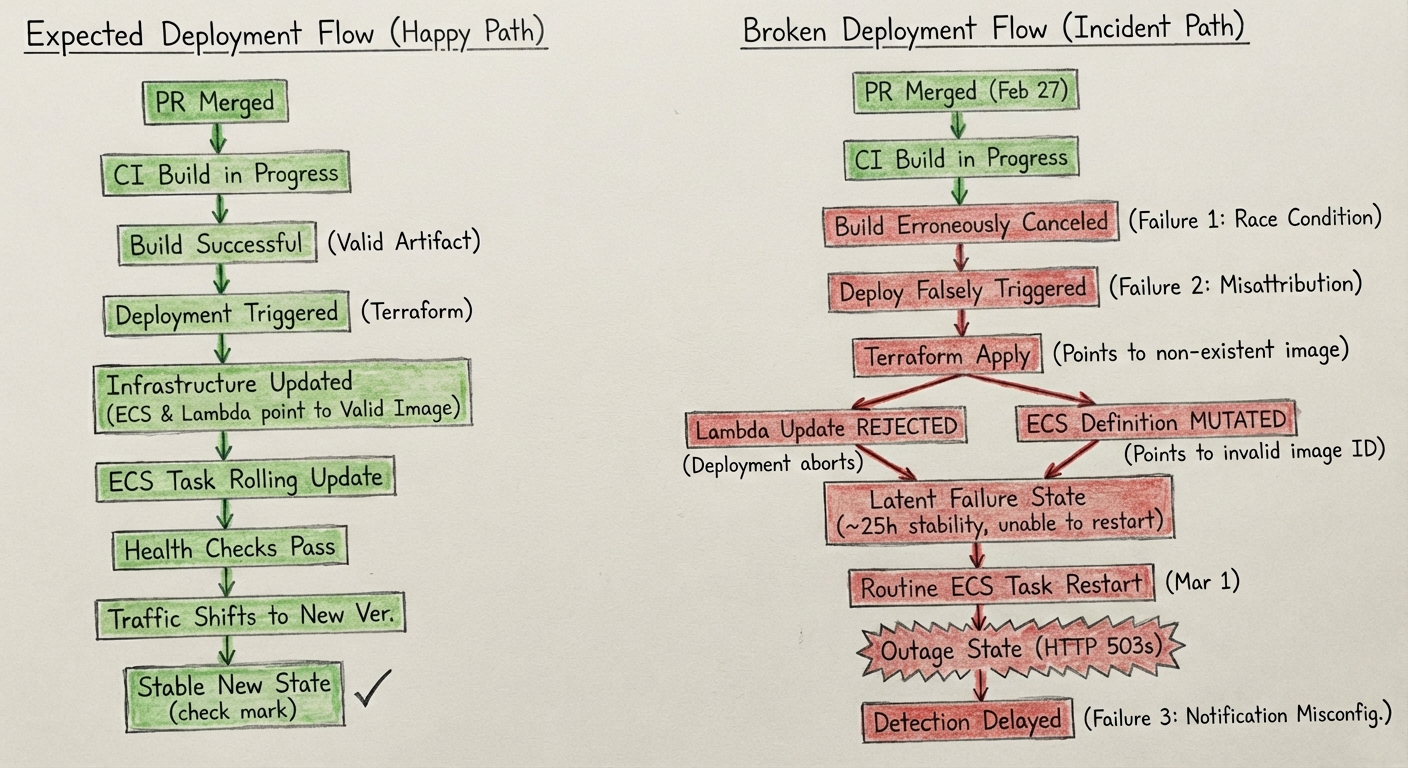
A race condition in our CI systems, with excessively aggressive concurrency control, resulted in a build job getting erroneously canceled during merge of a PR on February 27, 2026. A later deploy job falsely believed the build had completed because of a second issue in our CI system's attribution of build artifacts, and proceeded to roll out the change by updating AWS Lambda and ECS service definitions to point to a non-existent container ID.
This rollout was done with Terraform, which rejected the change to Lambda as invalid, aborting the deployment, but it had already mutated the ECS service definitions.
ECS's definitions were thus unable to put new tasks into production, and so traffic was not shifted, but the system was in a delicate state: if any ECS tasks exited, they would not be able to be restarted because their definition was invalid.
About 25 hours later, around 5:48 UTC on March 1, the ECS tasks gradually did begin to get restarted, but new tasks couldn't come up, so our frontend ingest load balancers began to respond with 503s to all ingest events, including webhooks and OpenTelemetry data.
How we found the problem
We use Firetiger (in a separate deployment) to monitor itself, so the system detected this issue at 6:00, 12 minutes after the problem materialized.
We have an agent instructed to make sure that our customers can integrate various data sources with the Firetiger platform successfully. It track all API surface area related to receiving data through systems like webhooks for abnormalities. This agent detected and flagged the problem, believing it to be isolated to GitHub webhook ingest, and attempted (more on that) to notify human operators.
At 7:47, the problem got worse, as more ingest tasks restarted. Our issue triaging subsystem (the same one used by all of our customers) identified that multiple detection agents had found problems related to ingestion (not just of GitHub webhooks) and also identified that many other agents had found a major drop in traffic. These all got coalesced into one issue, which was easily able to dig in and find the root cause, identifying the bad version in ECR.

Once the issue was found and we were alerted to it, we were able to quickly resolve it by pointing Claude Code at the Firetiger issue report. A snippet of that screenshot appears in the above screenshot. Using an MCP connection, as well as AWS and Github CLI access, we were able to find the broken deployment. We rebuilt the image, re-ran deploy scripts, and returned to a healthy state.
Second issue: internal misconfiguration of notifications
Despite the good performance of our agents in finding the issue, it still took us about 8 hours to be notified of the problem. This was due to a second issue in our system. Late on Friday night, one of our engineers was working on our internal Firetiger deployment's issue notification system.
While working on testing a new feature for users (a system for attributing issues to which deployment caused the issue), they repeatedly had to delete and remake a policy document used to control where notifications could get sent. Inadvertently, they left this in a state that hid notifications from our normal incident management channels, which resulted in the long period in which we didn't detect the issue.
What we learned
We learned a bunch of things from this incident that we're going to carry forward.
First, we've taken a critical look at our CI system and its build steps. Using the context provided by Firetiger, Claude Code developed a change to address the race condition that was the root cause of this failure.
Second, this is a clear case where Firetiger infrastructure should even be self-healing than it currently is; our agent triage system knew just what the problem was, and would have rolled back if we had given it the tools and connections to do so. We're going to work on improving Firetiger agents to be able to do this, and plan to make the same auto-rollback features available to all customers.
Third, we are granting our agent expanded permissions to access GitHub and manipulate our own deployments. In this particular case, Firetiger would have been able to do better than rolling back; it likely could have repaired the build state by rerunning the right jobs. We're bullish on the ability of agents to do complex tasks, if they are broken down into the right steps (it's kind of our thing) and we think this is a good use case.
An outage of this severity is painful, particularly for Firetiger customers who depend on us for operational health. We take our responsibilities seriously, but also view this as an important moment to improve our operations. Thanks for using Firetiger!