
We built an observability database for agents, not humans

Firetiger helps you engineer outcomes: we build AI agents that operate and improve your software. To operate and improve software, you need “observability”: visibility into what your software is actually doing. To make observability possible, you need a data layer that lets you ask questions of your telemetry: logs, metrics, traces, events… you name it.
Many observability datastores and time-series databases have been conceived over the years, and boy, do they have their differences. But there is one thing they all have in common: they were designed for people. People are busy, impatient, and demand low latency from their observability datastore. The observability access pattern for people tends to look like: “Holy @*&! I just got paged, I’m staring at this dashboard with a lot of red, reading the docs on mysteryQL trying to figure out what the errors actually are, and I need query results PRONTO”
The thing is, people are not the only ones capable of observing software nowadays. The practice of observability and software operations is a ripe use case for a fleet of highly competent, infinitely patient AI agents. Slow queries that would frustrate a human investigation are insignificant to an agent that can run 10 investigations in parallel.
This idea, that humans and agents have different needs and expectations of an observability database, led us to create an observability datastore purpose-built for AI agents, not humans. This database is what makes Firetiger's outcome-engineering agents smart, and what allows us to offer near-unlimited data ingestion to pair with those agents, allowing them to do work and be effective without you worrying about cardinality and cost.
What Humans Want, What Agents Need
Traditional observability backends optimize for the dashboard experience, where the goal is sub-second query latency. Put simply: a query system can be fast, handle large amounts of complex (high-cardinality) data, or be cheap to operate. You can generally get two of these three characteristics at once, and anyone who has used Datadog or similar systems knows which tradeoff they chose: optimize for fast queries over large, complex datasets, with an even larger bill at the end of the month.
There are tricks you can use to chip away at the three-legged tradeoff above: pre-aggregating metrics, sampling data, pre-deciding what questions are worth asking so you can try to ingest the valuable stuff. Overall, to unblock humans, traditional systems tend to treat observability as a read-optimization problem.
But what do agents want out of their observability datastore? It turns out that the big unlock for agent-driven observability is less about fast queries, and more about exploring a rich dataset in parallel. In practice, their main requirements are:
- Agents are cardinality-hungry. They want the high-cardinality data you'd normally drop: individual trace IDs, per-request attributes, full tag sets. They are very patient. They will sift through it.
- Agents generate orders of magnitude more query volume. A human runs a handful of queries per investigation. An agent might run hundreds. So you trade one scaling problem (low-latency per query) for another (massive concurrent throughput).
- Agents still need fresh data. Stale data isn't useful just because the consumer is patient. So you can't just dump everything into an hourly batch pipeline and call it a day.
As is increasingly the case, the requirements of the agents became the marching orders for humans. It was time to build them a datastore.
The Firetiger Datastore
The astute reader will squint at the above agent requirements and notice that this all sounds a bit data lake-y. We agree.
At its core, Firetiger’s datastore is built on Apache Iceberg, with data stored as Parquet on S3, and most of the system implemented in Go. That was not an aesthetic choice. It was a consequence of the access pattern we were designing for, to let our agents observe the way they do best.
Cardinality: Keep the Interesting Data
The first requirement from agents was simple: give them access to all the data.
Iceberg plus Parquet gives us a columnar layout that is very good at selective reads. You can keep wide, high-cardinality telemetry and still avoid paying the price of reading every column on every query. Put it on S3, and it’s cheap to read and write the extra volume cardinality implies.
This all only works if the query engine is smart about what it touches. We built Confit SQL for this purpose. Confit is built upon DuckDB, with some extra functionality to take advantage of Iceberg metadata, and push filters as far down as possible (you can read more about how we built Confit here). We’re not trying to blow away some benchmark with a single heroic query here. The point is to make broad exploration practical by making it cheap to rule out data you do not need to read in the first place.
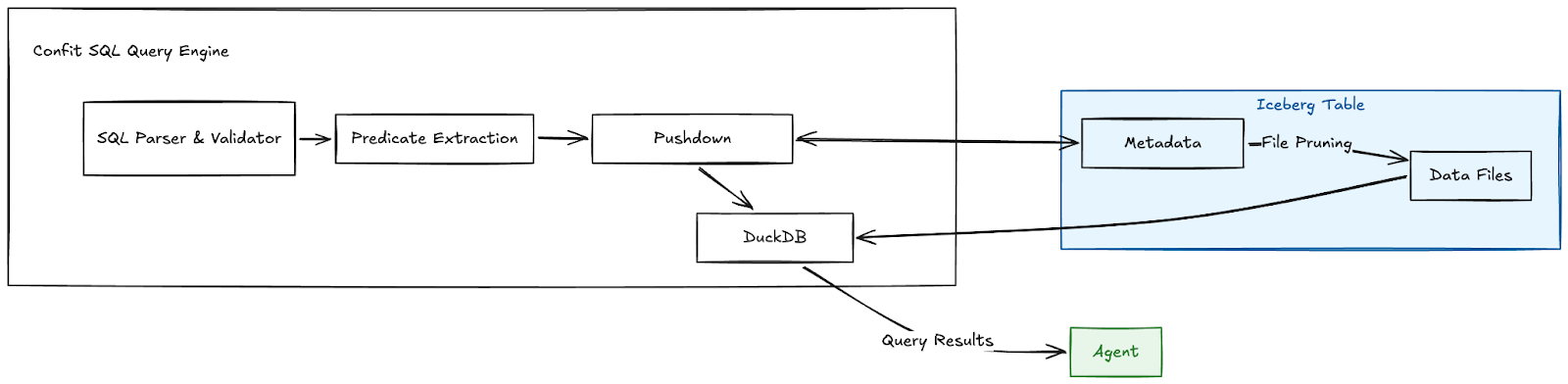
Query Volume: Let the Agents Explore
The second requirement is where agent access patterns really diverge from traditional observability.
A human might run a handful of queries while debugging an incident. An agent can run hundreds as it narrows hypotheses, compares time windows, pivots dimensions, and checks whether a pattern is real or a coincidence. The problem becomes: how do we run a lot of queries in parallel?
Data engineers will know there is a tried-and-true pattern here: Separate storage from compute. With Iceberg, storage is durable and shared. Compute can be provisioned independently on demand, so we run Confit’s query execution in a serverless function (e.g., on AWS Lambda).
A capable engine running on serverless compute provides the properties we need to pull off large query volume: horizontal scaling, and resource isolation. We can scale out to run many queries at once, with the isolation to ensure that any runaway query will not starve all the others. With this architecture, the constraint typically becomes S3 read bandwidth, which is rarely a chokepoint in practice.
Fresh Data: Real-time Iceberg is Where the Engineering Gets Real
The third big requirement is data freshness, and this is where things get fun. To understand why, let’s talk about Iceberg.
At the end of the day, an Iceberg table is a bunch of “files” (objects), structured in a specific way on object storage (S3), to represent some table with rows, columns and a schema. Every time you write new data (rows) to the table, you are writing new files to the table - some of those files are the actual data, some are metadata, all are part of the Iceberg table structure.
The fact that Iceberg represents tabular data as a bunch of objects on object storage is its strength. Not only is it cheap to store, it’s easy to read: Any compatible query engine (there are many) just needs to learn how to parse the table metadata, load data from the right data files, and execute a statement!
For our observability use case, the data needs to be ingested and made available with low latency, which means we need to quickly write small batches of data to our Iceberg tables. The problem is: the faster you write to the Iceberg table, the more small files begin to accumulate in the table on object storage. As more files accumulate in the table, queries need to read more files to execute. Each read takes time and resources. At some point, queries will slow down to a halt as they spend all their time trying to load tons of small files. What good is a table with fresh data if it is too slow to query?
This is an age-old problem in streaming data systems: The “small files problem”. Ultimately, the game is not just write data. The game is to make that data visible quickly without leaving behind a trail of fragmentation that destroys query performance later. That is, to maintain great write performance, we want to write lots of small files. To ensure great read performance, we need to read fewer large files.
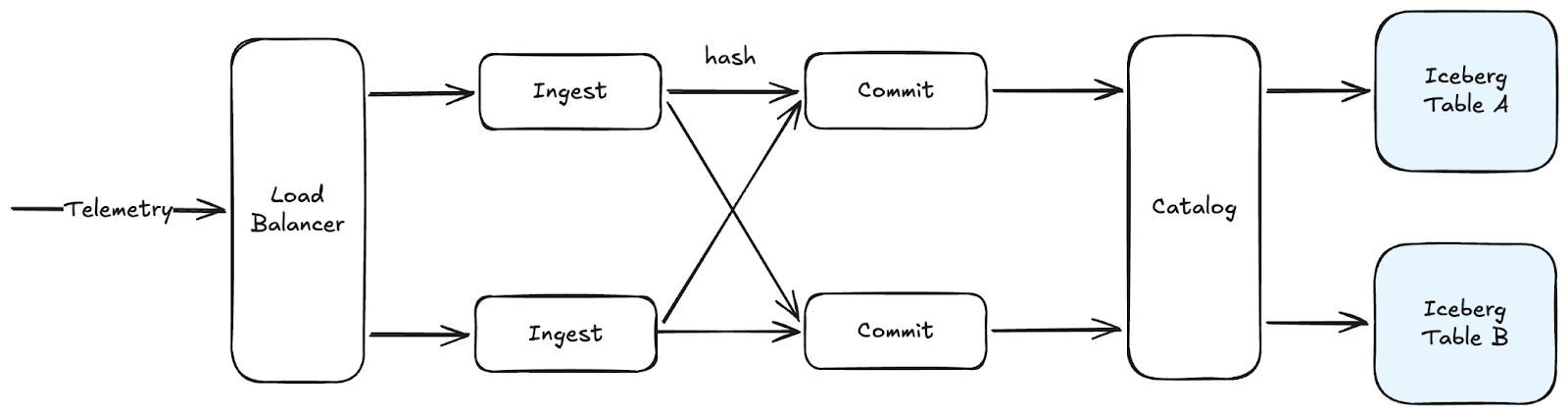
We addressed these challenges by building a distributed Iceberg ingest system designed for low-latency writes while minimizing downstream load on the read path.
The entry point is a dynamic fleet of ingest servers: it accepts OpenTelemetry, along with other common telemetry formats, and scales horizontally with ingest volume. From there, the ingest nodes combine concurrent requests into a smaller number of Iceberg commits: They first materialize and write data files to object storage independently, partitioned by table. Then, they use consistent hashing to choose a table’s commit leader, where each leader applies in-memory synchronization to merge concurrent writes into a single table commit operation against our Iceberg REST catalog.
This setup has a few important benefits:
- The Iceberg catalog backend is the ultimate coordinator, ensuring our table writes are atomic and consistent
- By merging many concurrent writes into one commit, we write fewer files to the table upfront: keeping the small file problem at bay.
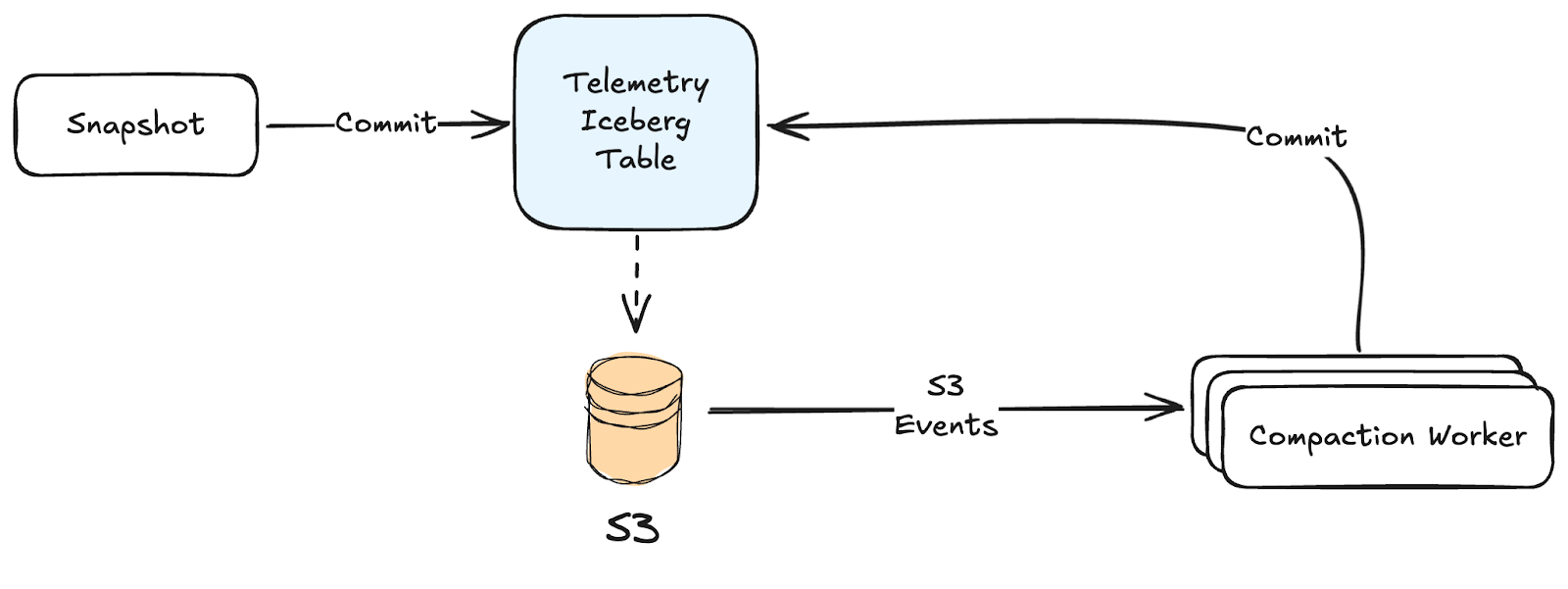
Unfortunately, all this work to merge table files at write time is not enough – we will still have too many small files on our hands, even after all the clever batching discussed above. To ensure streaming Iceberg tables remain efficient and queryable, they need to be continuously maintained after writing. Specifically:
- Data files need to be merged (aka compacted) even more, to ensure the table has fewer files that are easier to read, slice, and dice at query time
- Table snapshot metadata (effectively table “versions”) needs to be expired, so you don’t accumulate unbounded table metadata (files!) that needs to be loaded/processed every read
- Old data needs to be expired: it’s expensive and typically not useful to keep data around forever, so we enforce data retention to expire old table data
- Orphaned objects need to be cleaned up: as you expire table snapshots and data, old and unused objects will accumulate in S3. To manage costs, we need to delete these orphaned objects
In total, these are not nice-to-have optimizations. Each is essential to maintaining efficient, usable, real-time Iceberg tables.
We learned this the hard way. We really didn’t want to solve all of these problems ourselves, and initially reached for off-the-shelf solutions. As an example, AWS Glue provides built-in Compaction. In practice, Glue’s optimization jobs could not keep up with the volume and shape of our streaming writes.
So we ended up building our own Iceberg optimization layer, responsible for compacting many small files into fewer large ones, expiring old snapshots so metadata stays manageable, and cleaning up orphaned files that are no longer needed.
Snapshot expiration and orphan cleanup are pretty straightforward: they are essentially scheduled jobs that load and process table metadata.
Data file compaction is more complex. To keep up with our ingest volume, our compaction system is event-driven: it consumes S3 Event Notifications (or equivalent object change notifications on other cloud providers) for new table writes, then plans and applies data file compactions in parallel (also on serverless, Lambda-like primitives).
Building Agents, Building for Agents
The future of observing and operating production software will not involve humans hacking through a jungle of dilapidated dashboards, and confusing query languages - even if they’re fast. Instead, humans will be focused on engineering outcomes for users, while well-equipped AI agents use purpose-built tools to observe, triage, and act upon production issues.
At Firetiger, our datastore is one such tool: It allows users to send us unlimited, high cardinality telemetry data, while enabling our agents to ask questions and operate software for real people at real companies with real problems.
It’s worth noting we’ve barely scratched the surface explaining our data infrastructure in this blog post. Building an agent-first observability datastore brings many other fun challenges, including:
- Schema inference: schematizing unstructured telemetry data in intelligent ways makes table management, queries, and general agent operations much more efficient
- Data discoverability for agents: Agents need to be able to discover what telemetry is available, why and how to use it, including use cases that require very low write-to-read latency
- Multi-tenant data isolation and access: so users and agents alike have access to the appropriate data
And more. Stories for another time!
It turns out that AI hasn’t fully cooked systems engineering (yet) - we are hiring!